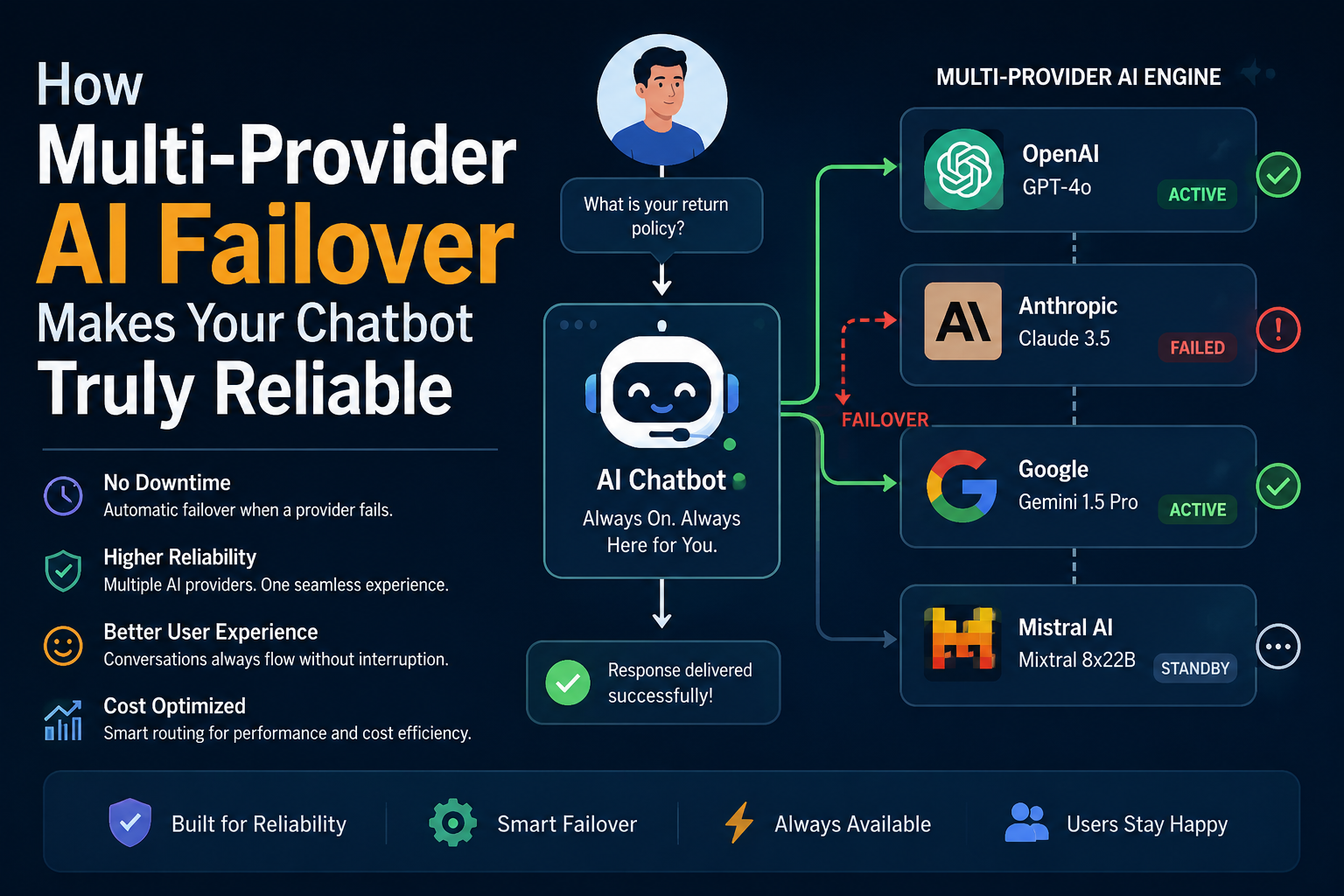
Reliability has become the decisive factor for conversational interfaces. A chatbot that stalls during a crucial transaction can damage brand reputation as quickly as a broken checkout page. While many companies rely on a single large‑language model (LLM) provider, the growing incidence of service outages, latency spikes, and model‑specific blind spots makes that approach risky. Multi‑provider AI failover—the practice of routing requests across two or more LLM services—offers a pragmatic path to true reliability without sacrificing innovation.
Why a Single Provider Is a Single Point of Failure
LLM services are complex cloud offerings that share the same vulnerabilities as any SaaS product: network congestion, maintenance windows, and sudden traffic spikes can all cause temporary unavailability. When a chatbot depends on a lone provider, any interruption propagates directly to the end‑user.
Recent Outage Examples
- OpenAI downtime (November 2023) – A regional outage in the United States prevented thousands of e‑commerce sites from processing support tickets, resulting in an estimated $1.2 million in lost revenue.
- Google Vertex AI latency surge (April 2024) – A spike in latency caused a major travel booking platform to experience 30‑second response times, prompting users to abandon the conversation.
- Anthropic rate limiting (June 2024) – An unexpected throttling event forced a fintech startup to fall back to manual handling, increasing operational overhead by 18 %.
These incidents illustrate that even the most reputable providers cannot guarantee uninterrupted service. The solution—redundancy—has long protected traditional infrastructure; it now needs to be applied to AI‑driven experiences.
Understanding Multi-Provider AI Failover
At its core, multi‑provider failover duplicates the request path: the chatbot first sends a prompt to the primary LLM. If the response does not arrive within a predefined threshold or returns an error, the system automatically forwards the same prompt to a secondary (or tertiary) provider. The chosen answer is then delivered to the user, often after a brief consistency check.
How the Routing Logic Works
- Health Check – Continuous ping or synthetic query monitors evaluate each provider’s latency and error rate.
- Primary Selection – The provider with the best recent performance, cost per token, and model alignment becomes the primary target.
- Timeout Trigger – If the primary response exceeds the failover timeout (commonly 800 ms for real‑time chat), the request is duplicated to the secondary provider.
- Result Reconciliation – Optional logic compares both answers; if they differ significantly, the system may select the higher‑confidence response or invoke a fallback message.
- Logging & Feedback – Every switch is logged for analytics, enabling continuous refinement of timeout thresholds and provider weighting.
Common Architectural Patterns
- Parallel Invocation – Send the prompt to all providers simultaneously and use the fastest valid response. This reduces latency but increases cost.
- Sequential Failover – Attempt the primary provider first; only on failure does the system call the secondary. This balances cost and reliability.
- Hybrid Weighted Routing – Distribute traffic based on a weighted score that reflects price, latency, and model performance, allowing dynamic load balancing across providers.
Real‑World Implementations
Several forward‑thinking companies have already integrated multi‑provider failover into production chatbots, turning reliability into a competitive advantage.
FinTech Chatbot: OpenAI + Anthropic
A rapidly growing peer‑to‑peer payment platform needed a chatbot that could handle transaction queries 24/7. The engineering team built a failover layer that prefers gpt‑4o for its nuanced reasoning but automatically falls back to Anthropic’s Claude‑3.5 when latency exceeds 700 ms. Since deployment, the bot’s mean time to recovery (MTTR) dropped from 12 minutes (single‑provider) to under 30 seconds, and the platform reported a 22 % reduction in support tickets escalated to human agents.
E‑Commerce Support Bot: Google Vertex AI + IBM Watson
Shopify’s flagship support assistant leverages Vertex AI for product recommendations and Watson for order‑status retrieval. The failover strategy routes order‑related intents first to Watson because of its tighter integration with inventory APIs. If Watson returns an error, the assistant uses Vertex to generate a generic “I’m checking that for you” response while a background process retries the original request. This design prevented a major sales‑day outage when Watson experienced a regional outage, preserving an estimated $3 million in sales.
Benefits Beyond Uptime
Reliability is just the starting point. Multi‑provider failover also unlocks strategic advantages that influence cost, performance, and user perception.
- Cost Optimization – By routing low‑complexity queries to a cheaper provider (e.g., a fine‑tuned open‑source model) and reserving premium models for high‑value interactions, companies can reduce average token cost by 15‑30 %.
- Model Diversity & Bias Mitigation – Different providers have distinct training data and safety filters. Switching between them can smooth out systematic biases, delivering more balanced responses.
- Performance Scaling – During traffic spikes, secondary providers absorb excess load, preventing throttling and maintaining response time SLAs.
- Future‑Proofing – As new models enter the market, adding them as additional failover options is straightforward, protecting investments in existing AI infrastructure.
Implementation Checklist
Before launching a failover‑enabled chatbot, ensure the following steps are completed:
- Provider Evaluation – Compare latency, pricing, token limits, and content‑safety policies. Document a decision matrix.
- Latency Benchmarking – Run synthetic queries from your production region to each provider; record 95th‑percentile response times.
- Define Failover Thresholds – Set timeouts based on user experience goals (e.g., ≤ 800 ms for typing‑like responses).
- Develop Routing Middleware – Implement a stateless service that handles health checks, timeout detection, and provider selection.
- Integrate Consistency Checks – If using parallel invocation, decide how to reconcile divergent answers (confidence scoring, rule‑based overrides).
- Monitoring & Alerting – Track failover frequency, error rates, and cost per token; trigger alerts when secondary usage spikes unexpectedly.
- Run A/B Tests – Compare user satisfaction metrics (CSAT, NPS) between single‑provider and failover configurations.
- Document Fallback Messaging – Craft transparent messages for cases when both providers fail, maintaining trust.
Design and UX Considerations
Technical robustness must be paired with a seamless user experience. Here are key design principles:
- Consistent Tone – Use a style guide that normalizes language across providers, ensuring the bot sounds like a single personality.
- Graceful Degradation – When both providers are unavailable, display an empathetic “I’m experiencing technical issues, please try again shortly.” Avoid generic error codes.
- Progress Indicators – Show a typing animation if the request exceeds the typical latency window, reducing perceived waiting time.
- Transparency – For regulated sectors (e.g., banking), disclose that multiple AI services are used for continuity, reinforcing compliance.
Measuring Reliability
To demonstrate the impact of failover, track these metrics over a 30‑day window:
| MTTR (Mean Time to Recovery) | Average time from detection of a primary failure to successful response delivery. |
| Availability (%) | Percentage of user interactions that receive a response within the defined SLA. |
| Error Rate | Ratio of failed requests (both primary and secondary) to total attempts. |
| Cost per Interaction | Total token spend divided by number of successful conversations. |
| CSAT Improvement | Change in post‑chat satisfaction scores after failover deployment. |
Companies that publish these numbers often see investor confidence rise, as reliability directly correlates with user retention and revenue growth.
Future Outlook: Towards AI Federation
As the ecosystem matures, we can anticipate standardized protocols for AI federation that abstract provider specifics behind a common API. Initiatives such as the OpenAI Interoperability Initiative and the Model Mesh Consortium aim to define health‑check schemas, token‑pricing descriptors, and safety‑policy negotiation formats. When these standards settle, integrating a new provider will be as simple as adding an entry to a configuration file, further lowering the barrier to true multi‑provider resilience.
Conclusion
Chatbots have evolved from novelty widgets to mission‑critical customer touchpoints. Relying on a single LLM provider exposes businesses to avoidable downtime, brand damage, and hidden costs. Multi‑provider AI failover transforms reliability from a hopeful aspiration into a measurable, repeatable engineering practice. By combining health monitoring, intelligent routing, and thoughtful UX design, startups and established enterprises can deliver conversational experiences that remain responsive—even when individual AI services falter. The result is not just higher availability; it is a stronger reputation, lower operational risk, and a competitive edge in an increasingly AI‑driven market.